PiFlow是一个扩展性强,性能优越,简单易用的大数据流水线系统,提供了100+的数据处理组件,包括Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等,欢迎下载使用!
软件特色
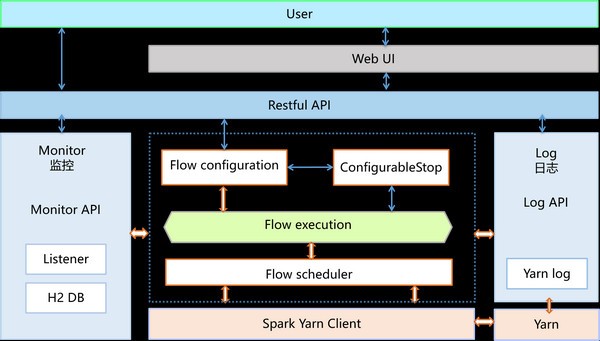
可视化配置流水线监控流水线查看流水线日志检查点功能支持自定义开发数据处理组件基于分布式计算引擎Spark开发集成了微生物领域的相关算法使用方法
解压piflow-server-v0.9.tar.gz:tar -zxvf piflow-server-v0.9.tar.gz编辑配置文件config.properties运行、停止、重启PiFlow Serverstart.sh、stop.sh、 restart.sh、 status.sh测试 PiFlow Server设置环境变量 PIFLOW_HOMEvim /etc/profileexport PIFLOW_HOME=/yourPiflowPath/binexport PATH=PATH:PIFLOW_HOME/bin运行如下命令piflow flow start example/mockDataFlow.jsonpiflow flow stop appIDpiflow flow info appIDpiflow flow log appIDpiflow flowGroup start example/mockDataGroup.jsonpiflow flowGroup stop groupIdpiflow flowGroup info groupId如何配置config.properties#spark and yarn configspark.master=yarnspark.deploy.mode=cluster#hdfs default file systemfs.defaultFS=hdfs://10.0.86.191:9000#yarn resourcemanager.hostnameyarn.resourcemanager.hostname=10.0.86.191#if you want to use hive, set hive metastore uris#hive.metastore.uris=thrift://10.0.88.71:9083#show data in log, set 0 if you do not want to show data in logsdata.show=10#server portserver.port=8002#h2db porth2.port=50002以上就是快连软件站小编今日为大家带来的PiFlow(大数据流水线系统),更多软件下载尽在快连软件站。
网友留言(0)